



Low-Rank Adaptation (LoRA): Technical Deep Dive into Parameter-Efficient Fine-Tuning for Large Language Models
Low rank adaptation (LoRA) is a method to retrain an LLM so it performs well on a specific task. Discover how LoRA allows you to use the language model and train it quickly and easily for your needs.

Introduction to LoRA: The Escalating Challenge of Fine-Tuning LLMs
Large Language Models (LLMs), such as GPT and Claude, are very good at generating text, understanding language, and handling a wide array of natural language processing tasks. They are trained on vast amounts of data, which helps them get a general sense of language and do well on many tasks without extra training.
However, these models often require fine-tuning to achieve high performance on specific domains or specialized tasks like turning text into code. This extra training helps them work better in those particular areas.
LLMs are incredibly large and complex, sometimes containing billions or even trillions of parameters. This makes them difficult to deploy and adapt practically. The traditional way to fine-tune LLMs involves retraining all their parameters, which is very slow, expensive, and requires a lot of computing power. Because of resource intensity demands, it's been difficult to make these models more available and widely used for personalized purposes. This is where Low-Rank Adaptation (LoRA) comes in—a quicker and more efficient method for training large language models.
This article provides a detailed technical overview of low rank adaptation, exploring its core concepts and technical mechanisms. It also covers the role of low rank adaptation in democratizing the fine-tuning of LLMs.
What is low rank adaptation?
Low rank adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method used to reduce the resource demands of training large language models and other neural networks. PEFT allows customization of pre-trained LLMs for specific tasks by selectively updating only a small subset of the model's parameters, rather than fine-tuning all of them.
LoRA works by keeping the original pre-trained model weights unchanged. Instead of changing these vast, fixed weights, LoRA adds small, trainable rank decomposition matrices called 'adapter weights' into certain layers of the model. It primarily targets the attention weights within transformer architectures. During fine-tuning, only these small matrices are updated and trained, while the rest of the base model's parameters remain unchanged.
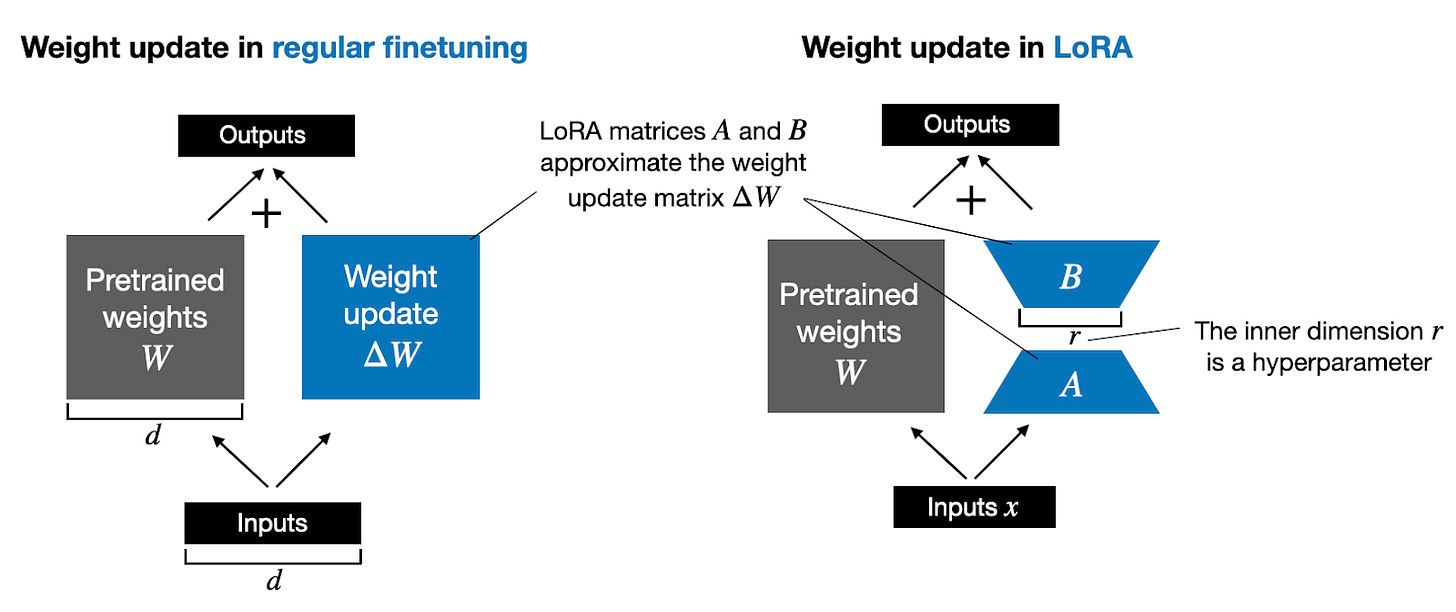
The foundational research on LoRA was initially published by Edward Hu, Yelong Shen, and their collaborators in their seminal 2021 paper, "LoRA: Low-Rank Adaptation Of Large Language Models". This work demonstrated that models fine-tuned using LoRA could achieve performance on par with or even better than fully fine-tuned base models across various benchmark tasks, despite utilizing a significantly smaller number of trainable parameters.
The Technical Mechanism of LoRA
Understanding Low-Rank Decomposition: The Role of Matrices A and B
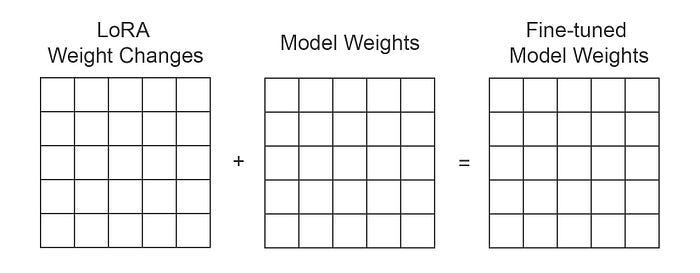
LoRA does not update the full-weight matrix (ΔW) directly during fine-tuning; instead, it approximates the update by decomposing the weight into two smaller matrices, A and B.
Mathematically, the update rule for a pre-trained weight matrix W0 becomes:
Wupdated = W0 + ΔW
where ΔW is approximated as:
ΔW ≈ B × A

Thus, the effective updated weight matrix for inference becomes:
Wupdated = W0 + B×A
For an original pre-trained weight matrix W ∈ ℝ^(d x k), where 'd' is the input dimension and 'k' is the output dimension, the update ΔW is approximated as the product of two matrices: B ∈ ℝ^(d x r) and A ∈ ℝ^(r x k). The variable 'r' represents the inner dimension or "rank" of the decomposition matrices, a crucial hyperparameter. The core of LoRA's efficiency is rooted in setting r << min(d, k). This condition dramatically reduces the number of trainable parameters compared to updating the full ΔW matrix.
For instance, if W is a 1000x5000 matrix (5,000,000 parameters), and a rank r=8 is chosen, then matrix A would be 1000x8 and matrix B would be 8x5000. The total parameters for A and B combined would be 1000*8 + 8*5000 = 8,000 + 40,000 = 48,000, a massive reduction from 5,000,000.

Conventionally, Matrix A is initialized with random values, often drawn from a Gaussian or Kaiming-uniform distribution, while Matrix B is initialized with zeros. This specific initialization ensures that the initial product BA is zero.
This design choice means that, at the start of fine-tuning, the LoRA adapters perform a "no-operation" transformation, leaving the pre-trained model's output completely unchanged. This is very important for keeping the training stable. If this "no-operation” starting point were not used, random initial settings could cause the model's output to change a lot right from the beginning. This could lead to unstable training and difficulty in reaching a good result.
This subtle initialization is important in many PEFT methods. It helps ensure that the new small changes don't disrupt the generalized knowledge of the pre-trained model. This makes LoRA more stable and effective because it can improve upon what the model already does well, instead of starting from scratch.
Merging LoRA Weights for Zero-Latency Inference
A significant practical advantage of LoRA is its ability to ensure no additional inference latency compared to the original pre-trained model. During inference, the small adapter weights (BA) can be seamlessly merged back into the base model's weights (W0) to form a single, modified weight matrix.
This merging process eliminates the need to load adapters separately during inference, ensuring that the fine-tuned model operates with the same computational graph and latency as the original pre-trained model. Libraries such as Hugging Face's PEFT provide utilities like merge_and_unload() to facilitate this process. This allows the newly combined model to function as a standalone, fine-tuned entity without any performance overhead.
Why use low-rank adaptation for LLMs?
LoRA's approach to fine-tuning large language models yields several profound advantages that address the limitations of traditional methods, making LLM adaptation more efficient, accessible, and scalable. These benefits include:
Significant Reduction in Trainable Parameters and GPU Memory Requirements
LoRA dramatically reduces the number of parameters that require training. For instance, when applied to GPT-3 (175 billion parameters), LoRA has been shown to reduce the trainable parameters by approximately 10,000 times. This translates to a reduction from 175 billion to roughly 18 million trainable parameters for GPT-3. This substantial parameter reduction directly leads to a significant decrease in GPU memory usage, enabling a 3x reduction for GPT-3 175B compared to full fine-tuning. Across various models and types, memory usage can be reduced anywhere from 25% to 100%.
Accelerated Training and Deployment Efficiency
With significantly fewer trainable parameters, less computational power is required for the training process, resulting in faster training times. This acceleration enables fast experimentation and iteration cycles, allowing developers to quickly test and refine model adaptations.
Reduced Checkpoint Sizes and Enhanced Portability
Since only the small adapter weights (matrices A and B) are trained and modified, only these minimal components need to be stored for each fine-tuned model, reducing storage requirements. For example, the checkpoint size for a GPT-3 model fine-tuned with LoRA was reduced from 1 TB to a mere 25 MB. This efficiency makes checkpointing and sharing fine-tuned models considerably more manageable and allows for the creation of multiple lightweight and portable LoRA models, each tailored for various downstream tasks, all built upon a single frozen base model.
Modularity: Shared Base Models and Efficient Task Switching
A key architectural advantage of LoRA is its ability to allow a single base model to be shared and used to build numerous smaller LoRA modules, each designed for distinct new tasks. Because the original base model remains frozen, users can seamlessly switch between different tasks simply by replacing the active LoRA weight matrices. This cut the need to maintain multiple distinct, full-sized models for different applications, while still retaining the performance benefits of fine-tuning. This modularity enables rapid model switching at runtime without significant overhead.
LoRA versus QLoRA (Quantized LoRA): A Detailed Comparative Analysis
QLoRA is an advanced extension of LoRA that integrates 4-bit NormalFloat (NF4) quantization to achieve even more significant reductions in memory usage. It quantizes the pre-trained weights to a lower bit precision (e.g., 4-bit) while still enabling efficient fine-tuning of the LoRA adapters. This approach allows for the fine-tuning of very large models on a single graphics processing unit (GPU).
A detailed comparison of trade-offs between tuning speed, GPU memory use, and computational cost when choosing between LoRA and QLoRA is provided below.

Brief Overview of Advanced LoRA Variants
LoRA is simple and very effective, which has inspired a lot of research. Many different versions have been created to improve it further or solve specific problems.
QLoRA: As discussed, this is a quantized version of LoRA that achieves extreme memory reduction through 4-bit quantization.
AdaLoRA (Adaptive LoRA): This variant dynamically allocates and adapts the rank of its matrices during training, allowing for optimized performance across diverse tasks and model architectures. It aims to be exceptionally good at juggling different tasks and model architectures, optimizing itself on the fly.
X-LoRA (Mixture of LoRA experts): A strategic approach that combines multiple frozen LoRA adapters with a lightweight scaling matrix. This ensemble method is particularly effective for complex tasks, reducing trainable parameters while maintaining high adaptability.
VB-LoRA (Vector Bank LoRA): This variant introduces reusable vector banks, which are parameter stores designed to minimize duplication across adapters. This approach reduces communication overhead and makes multi-client deployment feasible at scale, addressing inefficiencies in storage and transmission.
DoRA (Weight-Decomposed LoRA): DoRA proposes a multiplicative decomposition of weights instead of LoRA's additive updates. This approach aims to scale and rotate weights. It leads to better convergence and smoother optimization paths without additional computational burden.
LoRA+: This variant addresses suboptimality in LoRA when applied to models with large embedding dimensions. It corrects this by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. It leads to improved performance (1-2% improvements) and fine-tuning speed (up to 2x speedup) at the same computational cost as LoRA.
CE-LoRA (Computation-Efficient LoRA): This algorithm identifies the computation of activation gradients as a primary bottleneck in LoRA's backward propagation. CE-LoRA enhances computational efficiency while preserving memory efficiency by using approximated matrix multiplication and a double-LoRA technique. It can achieve approximately 3.39x acceleration in computation compared to standard LoRA without notable performance degradation.
PiSSA: This method initializes LoRA adapters using principal singular values and singular vectors, leading to more rapid convergence and superior performance compared to LoRA. It also reduces quantization error compared to QLoRA.
CorDA: CorDA builds task-aware LoRA adapters from weight decomposition oriented by the context of the downstream task (instruction-previewed mode, IPM) or world knowledge to maintain (knowledge-preserved mode, KPM). KPM not only achieves better performance than LoRA but also mitigates catastrophic forgetting. IPM can further accelerate convergence and enhance fine-tuning performance when preserving pre-trained knowledge is not a concern.
OLoRA: OLoRA uses QR decomposition to initialize LoRA adapters, translating the base weights by a factor of their QR decompositions before training. This approach significantly improves stability, accelerates convergence speed, and achieves superior performance.
EVA: EVA performs Singular Value Decomposition (SVD) on input activations of each layer and uses right-singular vectors to initialize LoRA weights, making it a data-driven initialization scheme. It adaptively allocates ranks across layers based on their "explained variance ratio".
Implementation of LoRA
Implementing Low-Rank Adaptation (LoRA) for fine-tuning large language models is streamlined by libraries such as Hugging Face's PEFT (Parameter-Efficient Fine-tuning) library. This section outlines the typical steps involved in applying LoRA to a pre-trained LLM, from model loading to inference.
1. Prerequisites and Environment Setup
Before diving into the fine-tuning process, it's essential to set up the development environment. This typically involves installing key libraries that facilitate efficient model handling, quantization, dataset management, and the PEFT framework itself. Core libraries include bitsandbytes for efficient quantization, datasets for data loading and manipulation, accelerate for distributed training (if needed), and the transformers and peft libraries from Hugging Face, which provide the necessary model architectures and LoRA utilities.
!pip install -q datasets accelerate bitsandbytes !pip install -q git+https://github.com/huggingface/transformers.git@main git+https://github.com/huggingface/peft.git 2. Loading and Quantizing the Pre-trained Base Model
The first step is to select and load a suitable pre-trained base model. The choice of model depends heavily on the specific downstream task. For instance, models like Google's Flan-T5 are well-suited for sequence-to-sequence tasks such as summarization or translation, while causal language models are preferred for generative tasks.
To optimize memory usage, especially for larger models, it's common practice to load the model with quantized weights. Using 4-bit quantization, for example, can reduce the model's memory footprint by approximately 8x. This is achieved by configuring a BitsAndBytesConfig object, specifying parameters like load_in_4bit, bnb_4bit_use_double_quant, bnb_4bit_quant_type, and bnb_4bit_compute_dtype. This configuration is then passed during the model loading process, allowing the model to be loaded directly into a lower precision, significantly lowering GPU memory requirements.
import torch
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-base", quantization_config=bnb_config, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-base")3. Configuring and Applying LoRA Adapters
Once the base model is loaded, the next crucial step is to define and apply the LoRA configuration. This involves creating a LoraConfig object from the PEFT library, where key hyperparameters are specified:
r(Rank): This determines the dimensionality of the low-rank matrices (A and B). A higher rank allows for more expressive adaptations but increases the number of trainable parameters.lora_alpha: A scaling factor applied to the LoRA updates, often set as a multiple ofrto control the magnitude of the learned changes.target_modules: A list of specific modules (e.g.,'q','v','k','o'for query, value, key, and output projection matrices in attention layers, or'all-linear'for all linear layers) within the base model where LoRA adapters will be injected.lora_dropout: A dropout rate applied to the LoRA layers for regularization, helping to prevent overfitting.bias: Specifies how bias parameters are handled (e.g.,'none'to exclude bias training,'all'to train all biases, or'lora_only'to train biases only within LoRA modules).task_type: Defines the type of task the model is being fine-tuned for (e.g.,SEQ_2_SEQ_LMfor sequence-to-sequence models,CAUSAL_LMfor causal language models).
After defining the LoraConfig, the base model is prepared for k-bit training (if quantization was used) using prepare_model_for_kbit_training, and then wrapped with the LoRA configuration using the get_peft_model function. This process automatically injects the small, trainable A and B matrices into the specified target modules, freezing the original base model weights. A key benefit immediately visible at this stage is the drastic reduction in trainable parameters, often representing less than 1% of the original model's total parameters.
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
config = LoraConfig(
r=8, #attention heads
lora_alpha=32, #alpha scaling
target_modules=["q","v"],
lora_dropout=0.05,
bias="none",
task_type="SEQ_2_SEQ_LM"
)
# prepare int-4 model for training
model = prepare_model_for_kbit_training(model)
model_lora = get_peft_model(model, config)
print_trainable_parameters(model_lora4. Data Preparation for Training
With the LoRA-adapted model ready, the next step is to prepare the task-specific dataset. This typically involves loading the dataset (e.g., from the Hugging Face datasets library) and tokenizing the text data using the tokenizer associated with the pre-trained base model. The specific preprocessing steps, such as formatting inputs and targets for sequence-to-sequence tasks or handling causal language modeling, will depend on the nature of the dataset and the chosen base model.
from datasets import load_dataset
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)5. Defining Training Arguments
Training parameters are configured using the TrainingArguments class from the transformers library. This object allows for detailed control over the training process, including:
output_dir: Directory to save model checkpoints and logs.per_device_train_batch_size: Batch size per GPU.gradient_accumulation_steps: Number of steps to accumulate gradients before performing an optimizer step, effectively increasing the batch size.optim: The optimizer to use (e.g.,paged_adamw_32bitfor quantized training).learning_rate: The rate at which model weights are updated during training.num_train_epochsormax_steps: The number of training epochs or maximum training steps.fp16/bf16: Enables mixed-precision training for faster computation and reduced memory.gradient_checkpointing: A memory-saving technique that recomputes activations during the backward pass instead of storing them.
from transformers import TrainingArguments
training_arguments = TrainingArguments(
output_dir = "flan-t5-lora",
per_device_train_batch_size = 4,
gradient_accumulation_steps = 4,
optim = "paged_adamw_32bit",
save_steps = 10,
logging_steps = 10,
learning_rate = 2e-4,
fp16=True,
max_grad_norm = 0.3,
max_steps = 500,
warmup_ratio = 0.03,
group_by_length=True,
lr_scheduler_type = "constant",
gradient_checkpointing=True,
)6. Training the LoRA Model
The training loop is managed using the Trainer class from the transformers library. The Trainer simplifies the training process by handling optimization, logging, evaluation, and checkpointing. It takes the LoRA-adapted model, the defined training arguments, the prepared training dataset, and a data collator (e.g., DataCollatorForLanguageModeling for language modeling tasks) as inputs.
from transformers import Trainer, DataCollatorForLanguageModeling
trainer = Trainer(
model=model_lora,
train_dataset=data["train"],
args= training_arguments,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False
trainer.train()7. Saving and Loading LoRA Adapters for Inference
Upon completion of fine-tuning, only the small LoRA adapter weights need to be saved. These adapters are typically very small (e.g., around 30 MB for a Flan-T5 model), making them highly portable and easy to share or store. They can be pushed to model hubs (like Hugging Face Hub) or saved locally.
model.push_to_hub("asanthosh/flan-t5-lora",
use_auth_token=True,
commit_message="lora 100",
private=True)For inference, these saved LoRA adapters are loaded and then attached to the original pre-trained base model using the PeftModel class.
import torch
from peft import PeftModel, PeftConfig
peft_model_id = "asanthosh/flan-t5-lora"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-base", quantization_config=bnb_config, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-base")
# Load the Lora model
model = PeftModel.from_pretrained(model, peft_model_id)Hyperparameter Tuning Best Practices
Effective hyperparameter tuning is crucial for optimizing LoRA fine-tuning, aiming to increase accuracy while counteracting overfitting or underfitting.
Learning Rate: A typical range for LoRA fine-tuning is 2e-4 (0.0002) to 5e-6 (0.000005), with 2e-4 often serving as a recommended starting point. For longer training runs, a higher learning rate might work better, while lower rates are generally more appropriate for full fine-tuning. Unstable training trajectories can occur with overly high learning rates, impacting final model performance.
Epochs: For most instruction-based datasets, 1-3 epochs are generally recommended. Training for more than three epochs often yields diminishing returns and increases the risk of overfitting, where the model memorizes the training data rather than learning generalizable patterns.
LoRA Rank (r) and lora_alpha: r should typically be between 4 and 64.
lora_alpha should generally be at least equal to r. Increasing
r and lora_alpha can help address underfitting, making the model less generic.Effective Batch Size: A larger effective batch size generally leads to smoother, more stable training, while a smaller one may introduce more variance. The effective batch size is the product of batch_size and gradient_accumulation_steps. To avoid out-of-memory (OOM) errors, it is often advisable to set a smaller
batch_size and increase gradient_accumulation_steps to reach the target effective batch size.Regularization: To combat overfitting, techniques such as increasing weight_decay (e.g., 0.01 or 0.1) or lora_dropout (e.g., 0.1) can be employed. Early stopping based on validation loss can also prevent overfitting.
Dataset Quality: The quality and domain relevance of the training dataset are paramount. Clean, task-focused data can significantly reduce the sensitivity to other hyperparameters. Expanding the dataset with higher-quality open-source data can also mitigate overfitting.
Challenges of LoRA
While LoRA is an efficient training method, it is not without its challenges, and ongoing research continues to explore its limitations and potential enhancements. LoRA challenges include:
Intruder Dimensions: A primary finding in recent research is the presence of "intruder dimensions" in LoRA fine-tuned models. These are new, high-ranking singular vectors in the model's weight matrices that are approximately orthogonal to the singular vectors of the pre-trained model. Crucially, they do not appear during full fine-tuning, indicating a structural difference in how LoRA adapts models.
Lower Effective Rank: Even when LoRA is performed with a high-rank matrix, the effective rank of LoRA updates can be significantly lower than that of full fine-tuning solutions. This indicates that LoRA may not fully utilize its capacity, potentially explaining observed performance gaps on highly challenging tasks like code generation.
Impact of Alpha Scaling: The scaling factor α significantly impacts LoRA's behavior. When α is fixed (e.g., α=8) instead of being scaled with rank (α=2r), LoRA models, even at very high ranks, exhibit intruder dimensions and have a much smaller effective rank. This also leads to more forgetting of both the pre-training distribution and previously learned tasks during continual learning.
Increased Intruder Dimensions with Dataset Size: The total number of intruder dimensions added in a LoRA model grows proportionally with the size of the fine-tuning dataset, especially for higher ranks (e.g., r=8).
Conclusions
Low-Rank Adaptation (LoRA) stands as a transformative innovation in the field of machine learning, fundamentally fine-tuning large models. Its core mechanism, which involves freezing the vast majority of pre-trained weights and injecting small, trainable low-rank decomposition matrices, directly addresses the prohibitive computational and memory costs associated with traditional full fine-tuning. This approach has led to dramatic reductions in trainable parameters (e.g., 10,000x for GPT-3) and GPU memory requirements (e.g., 3x for GPT-3), making multi-billion parameter models feasible on more accessible hardware. LoRA has firmly established itself as an indispensable tool for adapting the immense power of large pre-trained models to specific real-world challenges, making advanced artificial intelligence more accessible and deployable.
Works cited
Mastering Low-Rank Adaptation (LoRA): Enhancing Large Language Models for Efficient Adaptation | DataCamp, https://www.datacamp.com/tutorial/mastering-low-rank-adaptation-lora-enhancing-large-language-models-for-efficient-adaptation
Parameter-Efficient Fine-Tuning for Foundation Models - arXiv, https://arxiv.org/html/2501.13787v1
LoRA: Low-Rank Adaptation for LLMs | Snorkel AI, https://snorkel.ai/blog/lora-low-rank-adaptation-for-llms/
Guide to fine-tuning LLMs using PEFT and LoRa techniques - Mercity AI, https://www.mercity.ai/blog-post/fine-tuning-llms-using-peft-and-lora
What is LoRA (Low-Rank Adaption)? | IBM, https://www.ibm.com/think/topics/lora
Low-rank Adaptation of Large Language Models—Implementation Guide - Nexla, accessed July 1, 2025, https://nexla.com/enterprise-ai/low-rank-adaptation-of-large-language-models/
LoRA: Low-Rank Adaptation Explained | Ultralytics, https://www.ultralytics.com/glossary/lora-low-rank-adaptation
Efficient Fine-Tuning of Large Language Models with LoRA | Artificial Intelligence - ARTiBA, https://www.artiba.org/blog/efficient-fine-tuning-of-large-language-models-with-lora
[2106.09685] LoRA: Low-Rank Adaptation of Large Language Models - ar5iv - arXiv, https://ar5iv.labs.arxiv.org/html/2106.09685
LoRA - Hugging Face, https://huggingface.co/docs/peft/main/conceptual_guides/lora
LoRA Hyperparameters Guide | Unsloth Documentation,, https://docs.unsloth.ai/get-started/fine-tuning-guide/lora-hyperparameters-guide
LoRA vs. QLoRA - Red Hat, https://www.redhat.com/en/topics/ai/lora-vs-qlora
LoRA and QLoRA recommendations for LLMs | Generative AI on ..., accessed July 1, 2025, https://cloud.google.com/vertex-ai/generative-ai/docs/model-garden/lora-qlora
CE-LoRA: Computation-Efficient LoRA Fine-Tuning for Language Models - arXiv, https://arxiv.org/html/2502.01378v1
[2502.01378] CE-LoRA: Computation-Efficient LoRA Fine-Tuning for Language Models, https://arxiv.org/abs/2502.01378
Make LoRA Great Again: Boosting LoRA with Adaptive Singular Values and Mixture-of-Experts Optimization Alignment - arXiv, https://arxiv.org/html/2502.16894v3